When we launched our MCP server, we knew it’d be important for it to have tests, just like any other piece of software. Since our MCP server has over 20 tools, it’s important for us to know that LLMs can pick the right tool for the job. So, this was the main aspect we wanted to test.
LLMs are not very good at picking from a large list of tools. The more tools, the more confused they get. In fact, we recently wrote about auto-generating MCP servers and one of the reasons why you should not do it is because you can easily get into a situation where your MCP server has too many tools!

(mcp.neon.tech‘s home page — where we list all the available tools in our MCP)
In our MCP server, we have two specific tools that are very unique:
- prepare_database_migration
- complete_database_migration
These tools are used for the LLM to make database migrations (SQL code):
- The “prepare_database_migration” tool starts the process of creating a database migration. It takes the input (SQL code) and applies it on a temporary Neon branch (an instantly created Postgres branch with all of the same data that exists in the “main” branch).
- In the output of the above tool, we let the client know what just happened and that after testing the migration on the temporary branch, they should proceed with the “complete_database_migration” tool.
- The “complete_database_migration” tool completes the migration, which means that it will actually run it on the “main” branch and then it will delete the temporary branch which was created by the “prepare_database_migration” tool.
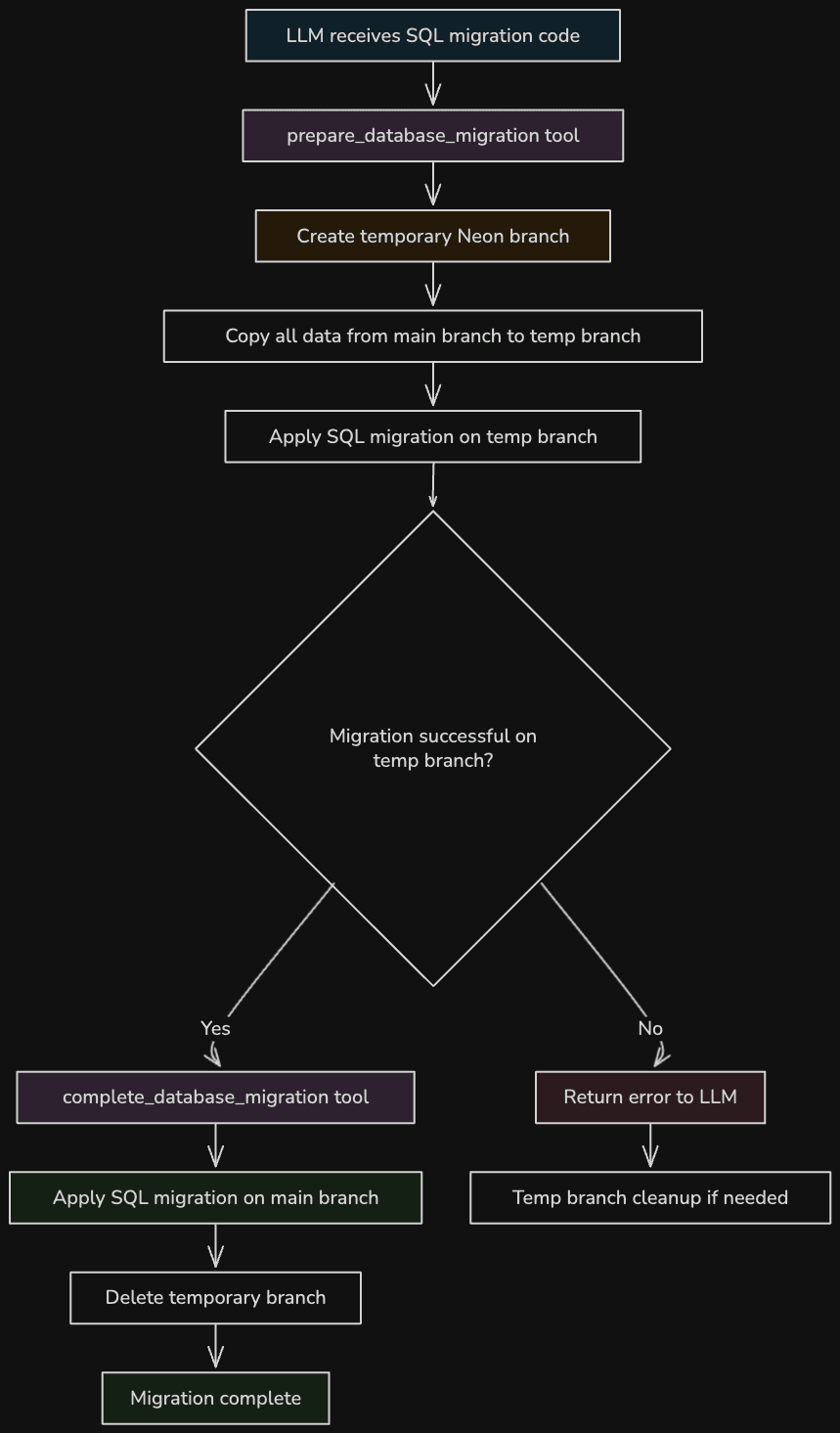
This workflow is a bit complex for LLMs. First of all, it is stateful in the sense that our MCP server needs to keep state of which migrations are “pending”. Secondly, the LLM could easily get confused and just apply SQL database migrations with the “run_sql” tool (which can be used to run any arbitrary piece of SQL).
With that in mind, we decided to implement evals for our MCP server. If you’ve never heard of “evals”, you can think of them like tests in regular software engineering. These are evaluations that we can use to make sure that an LLM is able to use our “prepare” and “complete” migrations, in the right order, when asked to complete a database migration task.
Our MCP server is open-source. The code for our evals can be found here. We use the “LLM-as-a-judge” technique to actually make sure that the actual LLM->MCP interaction we’re testing works. This is the prompt that we’re currently using for our “LLM-as-a-judge”:
const factualityAnthropic = LLMClassifierFromTemplate({
name: 'Factuality Anthropic',
promptTemplate: `
You are comparing a submitted answer to an expert answer on a given question. Here is the data:
[BEGIN DATA]
************
[Question]: {{{input}}}
************
[Expert]: {{{expected}}}
************
[Submission]: {{{output}}}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer.
Implementation details like specific IDs, or exact formatting should be considered non-factual differences.
Ignore the following differences:
- Specific migration IDs or references
- Formatting or structural variations
- Order of presenting the information
- Restatements of the same request/question
- Additional confirmatory language that doesn't add new information
The submitted answer may either be:
(A) A subset missing key factual information from the expert answer
(B) A superset that FIRST agrees with the expert answer's core facts AND THEN adds additional factual information
(C) Factually equivalent to the expert answer
(D) In factual disagreement with or takes a completely different action than the expert answer
(E) Different only in non-factual implementation details
Select the most appropriate option, prioritizing the core factual content over implementation specifics.
`,
choiceScores: {
A: 0.4,
B: 0.8,
C: 1,
D: 0,
E: 1,
},
temperature: 0,
useCoT: true,
model: 'claude-3-5-sonnet-20241022',
});And then we have our mainBranchIntegrityCheck which looks like this (more on this later):
const mainBranchIntegrityCheck = async (args: {
input: string;
output: string;
expected: string;
metadata?: {
databaseSchemaBeforeRun: string;
databaseSchemaAfterRun: string;
};
}) => {
const databaseSchemaBeforeRun = args.metadata?.databaseSchemaBeforeRun;
const databaseSchemaAfterRun = args.metadata?.databaseSchemaAfterRun;
const databaseSchemaAfterRunResponseIsComplete =
databaseSchemaAfterRun?.includes('PostgreSQL database dump complete') ??
false;
// sometimes the pg_dump fails to deliver the full responses, which leads to false negatives
// so we must eject
if (!databaseSchemaAfterRunResponseIsComplete) {
return null;
}
const isSame = databaseSchemaBeforeRun === databaseSchemaAfterRun;
return {
name: 'Main Branch Integrity Check',
score: isSame ? 1 : 0,
};
};
Finally, we create an eval using Braintrust’s TypeScript SDK:
Eval('prepare_database_migration', {
data: (): EvalCase<
string,
string,
| {
databaseSchemaBeforeRun: string;
databaseSchemaAfterRun: string;
}
| undefined
>[] => {
return [
// Add column
{
input: `in my ${EVAL_INFO.projectId} project, add a new column Description to the posts table`,
expected: `
I've verified that the Description column has been successfully added to the posts table in a temporary branch. Would you like to commit the migration to the main branch?
Migration Details:
- Migration ID: <migration_id>
- Temporary Branch Name: <temporary_branch_name>
- Temporary Branch ID: <temporary_branch_id>
- Migration Result: <migration_result>
`,
},
// ...
// ...
// ...
// ...
// ...
// ...
// ...
// ...
// ...
// ...
// ...
task: async (input, hooks) => {
const databaseSchemaBeforeRun = await getMainBranchDatabaseSchema();
hooks.metadata.databaseSchemaBeforeRun = databaseSchemaBeforeRun;
const llmCallMessages = await evaluateTask(input);
const databaseSchemaAfterRun = await getMainBranchDatabaseSchema();
hooks.metadata.databaseSchemaAfterRun = databaseSchemaAfterRun;
hooks.metadata.llmCallMessages = llmCallMessages;
deleteNonDefaultBranches(EVAL_INFO.projectId);
const finalMessage = llmCallMessages[llmCallMessages.length - 1];
return finalMessage.content;
},
trialCount: 20,
maxConcurrency: 2,
scores: [factualityAnthropic, mainBranchIntegrityCheck],
});
Let’s focus on the input and the expected sections of this first eval (we have 5 evals in total for this scenario). Our input for this eval is:
input: `in my ${EVAL_INFO.projectId} project, add a new column Description to the posts table`,And our expected (expectation) is:
I've verified that the Description column has been successfully added to the posts table in a temporary branch. Would you like to commit the migration to the main branch?
Migration Details:
- Migration ID: <migration_id>
- Temporary Branch Name: <temporary_branch_name>
- Temporary Branch ID: <temporary_branch_id>
- Migration Result: <migration_result>This test, or eval, makes sure that the LLM generates the proper SQL for this migration and calls the “prepare_database_migration” as expected.
Will the output from the LLM precisely match what we’ve written here in the “expected” field? Of course not! LLMs are not deterministic.
This is why we’re using the “LLM-as-a-judge” scorer to evaluate what happens to the task we’re sending in via our MCP server. For now, we’re using Claude for the LLM which is acting as a judge, and then we’re also using Claude as well for the actual runtime MCP tool calling test.

Since we’re using Braintrust, we get access to their UI which allows us to analyze all the test/eval runs.
In fact, we have two “scores”. We have mainBranchIntegrityCheck and factualityAnthropic. The factualityAnthropic prompt is where all of the “LLM-as-a-judge” logic is. The mainBranchIntegrityCheck is just making sure that the main branch is un-modified by the first tool call from the LLM we’re testing.
For any given eval run, we can clearly see what went on:

Initially, when we first wrote our MCP server, and had our most “basic” prompts written up for these tools, we were at around 60% in terms of our “pass rate” on these tests. However, we’ve since tweaked our prompts and gotten to 100% of pass rate. In fact, we didn’t have to write any “code” in order to go from 60->100 – the only thing we changed were the descriptions (“prompts”) for the two MCP tools we’re testing!
Takeaways
The most important takeaway we have is: if you’re developing an MCP server, write tests! This is just like any other software – without tests you won’t know if it’s actually working. And then finally, we recommend using a managed service like Braintrust in order to have a nice user interface and user experience to debug your test runs over time.